Pár évvel ezelőtt szembejött egy pici belsős projekt, ahol jó lett volna párhuzamosítani a feladatokat. Gondoltam megnézem, hogyan lehet ezt megoldani Docker segítségével és meglepően gyorsan és könnyedén sikerült. Ezt szeretném most bemutatni nektek.
Feladat
Azt kellett megoldani, hogy a megadott URL-en található weboldalról megtudjuk, milyen verziójú Drupal-t használ és az mennyire elavult. Ezt a legtöbb Drupalos oldalnál egy egyszerű curl hívás és némi parancssori mágia segítségével meg lehet oldani.
Probléma
Ami a problémát jelenti, hogy meg kell várni azt a viszonylag hosszú időt, amíg az adott oldal betöltődik, vagyis a TCP csomagok megérkeznek. Ezalatt a várakozás alatt a gép processzora nem csinál semmit, az adott process gyakorlatilag alszik. Ekkor egy weboldal feldolgozás 2-3 másodperc, amiből a tényleges munka, amíg a processzor dolgozik az csak 2-3 századmásodperc.
Ha 100 processzt indítunk el, akkor 2-300 másodperc lesz az összes várakozás és 2-3 másodperc a tényleges processzor idő. Ha ezeket egymás után indítjuk el, akkor 2-300 másodpercig fog futni a feldolgozás, de ha párhuzamosítjuk ezeket, akkor csak a processzor időkkel kell számolnunk és hozzá kell adnunk az első hálózati időt, így 4-5 másodperc alatt végezni fog a scriptünk.
Megoldás a párhuzamosítás
Egy nem párhuzamosított feldolgozás úgy fog kinézni, hogy vesszük az URL-ek listáját és végigmegyünk rajta egy ciklussal, amiben URL-enként meghívjuk a feldolgozást.
A párhuzamosításnál pedig lesznek workereink, amik figyelnek egy várakozási sort, egy job queue-t. Amennyiben abba új URL érkezik, akkor feldolgozzák az előbb is használt feldolgozó függvénnyel. Az eredeti ciklusunk pedig nem a feldolgozást hívja meg ciklikusan, hanem bedobálja az URL-eket a várakozási sorba.
Ha csak egy workerünk van, akkor ugyanott vagyunk ahol az első megoldásnál, csak lassabbak és bonyolultabbak leszünk. Vagyis nem egészen, mert lehetőségünk lesz könnyedén skálázni a rendszert. Ha sok URL van a várakozási sorban, akkor csak el kell indítunk még egy pár workert és máris előbb végzünk.
Természetesen nem minden feladatot lehet ilyen egyszerűen skálázni egy gépen, de hogy miket lehet és hogyan arra majd egy másik blogbejegyzésben szeretnénk kitérni.
A teszt alatt 200 párhuzamos processz dolgozott egy MacBook Air gépen.
Egy jobnak három állapota lehet: vagy vár a feldolgozásra, vagy éppen dolgozunk vele, vagy már készen van. A jobok állapotát három lista segítségével tesszük követhetővé, amiknek a neve: queue, run, done. A queue, ahova az elvégzendő job-ok kerülnek. Ez lesz a fentebb említett várakozási lista. A run, ahol az éppen feldolgozás alatt álló feladatok vannak. Ebben lesznek azok a job-ok is amik valamiért elhaltak. A done, amibe azok a jobok kerülnek amik elkészülnek. A run és done listák nem feltétlenül szükségesek, azokat azért hoztam létre, hogy lehessen látni, hogy a jobok milyen állapotban vannak.
Figyelem!
Az itt bemutatott megoldás nem alkalmas az éles környezetben való használatra!. A példáknak kizárólag a párhuzamosítás bemutatása a célja, az itt található kódok írásakor nem foglalkoztam biztonsági kérdésekkel ezért csak saját felelősségre használjátok!
Architektúra
Három konténeres környezetet építünk. A feladatokat egy Redis szerverben fogjuk nyilvántartani, mivel az kész megoldást ad, többek között erre is.
Lesz egy worker nevű konténer, ami a feladatokat fogja végrehajtani, ez az amit majd több példányban is elindítunk.
És végül indítunk egy monitor konténert, ami egyrészt mutatja a feladatok állapotát, másrészt itt kap helyet az a script amivel újabb és újabb feladatokat dobhatunk be.
Ugyan a dockeres kialakítás miatt lehetőségünk lenne több gépen is skálázni a megoldást Kubernetes vagy Swarm segítségével, most mégis egy egygépes megoldást mutatok docker-compose segítségével.
Fontos tudni, hogy a docker-compose.yml mindkét, 2.x és 3.x verziója is használható. Azok egymás mellett élnek, fejlődnek. A kettő között az a különbség, hogy a 2.x verzióban található beállítási lehetőségek inkább a fejlesztői vagy lokális környezetben való futtatáshoz jók, míg a 3.x verzió inkább a többgépes rendszerekhez alkalmasak.
A fenti architektúrát a docker-compose.yml írja le
version: "2.4"
services:
redis:
image: redis
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 1s
timeout: 3s
retries: 30
monitor:
build: monitor
depends_on:
redis:
condition: service_healthy
worker:
build: worker
depends_on:
redis:
condition: service_healthy
A három szervízről fentebb írtam. Mint látszik a redis konténerhez a hivatalos Redis imaget használom, kiegészítve egy healtcheck-el. A másik két konténert külön építjük meg, mivel azokat saját kóddal egészítjük ki.
Monitor
Nézzük mi van a monitor Dockerfile-jában:
FROM ubuntu
RUN apt-get update && apt-get install -y redis-tools
COPY init.sh /init.sh
COPY monitor.sh /monitor.sh
COPY add.sh /add.sh
ENTRYPOINT ["/init.sh"]
A második sorban telepítjük a redis-cli parancssoros redis klienst tartalmazó csomagot, majd bemásolunk pár bash scriptet és beállítjuk egyiket a belépési pontnak:
init.sh
#!/bin/bash
REDIS_CLI="redis-cli -h redis"
$REDIS_CLI DEL queue
$REDIS_CLI DEL run
$REDIS_CLI DEL done
exec /monitor.sh
A script semmi mást nem csinál, mint törli a három listát, hogy az esetleges korábbi futások eredménye ne okozzon problémát. Ezután elindítja a monitort. Mint látszik a redis szerver elérhetősége bele van drótozva a rendszerbe, de mivel ezek a szkriptek egy zárt, külön az alkalmazás részére létrehozott hálózaton fognak üzemelni, ezzel nem foglalkozunk.
montior.sh
A monitor a célja, hogy időről-időre követni tudjuk, hogyan áll a teljes folyamat. Erre itt azt a megoldást választottam, hogy 2 másodpercenként lekérem a három redis által kezelt lista hosszát, és kiírom az konzolra. Így:
#!/bin/bash
REDIS_CLI="redis-cli -h redis"
while true; do
QUEUE=$($REDIS_CLI LLEN queue)
RUN=$($REDIS_CLI LLEN run)
DONE=$($REDIS_CLI LLEN done)
echo "Queue: $QUEUE, run: $RUN, done: $DONE"
sleep 2
done
Azért, hogy könnyedén tudjunk újabb feladatot hozzáadni a rendszerhez elhelyeztem egy add.sh-t is:
#!/bin/bash
REDIS_CLI="redis-cli -h redis"
for JOB in "$@"
do
$REDIS_CLI LPUSH queue $JOB
done
Ennek csak annyi dolga van, hogy a parancssorban kapott értékeket betegye az elvégzendő feladatok közé. Ez az egyik pont, amit semmilyen körülmények között nem engednék futtatni éles környezetben. Mint látjátok, a kapott argumentumokat escape-elése nincs megoldva, így a feladat nem tartalmazhat idézőjelet ("), valamint jelen formájában könnyedén tudunk bármilyen parancsot futtatni a segítségével. Ettől függetlenül a job bármi lehet. A fent tárgyalt példában sima url-ek voltak a job-ok
Worker
Dockerfile
FROM ubuntu
RUN apt-get update && apt-get install -y redis-tools
COPY worker.sh /worker.sh
COPY script.sh /script.sh
ENTRYPOINT ["/worker.sh"]
Nagy különbség nincs az előzőhöz képest, csak mási két fájlt használ.
worker.sh
#!/bin/bash
REDIS_CLI="redis-cli -h redis"
while true; do
JOB=$($REDIS_CLI BRPOPLPUSH queue run 0)
/script.sh $JOB
$REDIS_CLI LREM run 1 $JOB
$REDIS_CLI RPUSH done $JOB
done
Ez a bash script is egy végtelen ciklusban ismétli a következőket. Első körben lekéri a job-ot a redisből. Ehhez a BRPOPLPUSH parancsot használja, ami kiveszi a queue-ból a következő feladatot és egyből átteszi a run sorba. Fontos, hogy ez egy atomi művelet, így nem fordulhat elő az, hogy egyszerre két worker kezd el dolgozni ugyanazon a feladaton. További előnye ennek a megoldásnak, hogy ha üres a lista, automatikusan várakoztatja a workert, így ezzel a problémával sem kell külön foglalkoznunk.,
Ezután a feladatot átadja a tényleges feldolgozást végző script.sh-nak majd, ha az végzett törli a job-ot a run sorból és átrakja a done sorba. Itt, szemben az előbbi esettel nem a következő tetszőleges feladattal kell foglalkoznom, hanem egy konkrét éppen a worker által feldolgozott jobbal dolgozom. Azt törlöm ki a run listából és teszem át a done listába.
A worker.sh nem foglalkozik hibakezeléssel, így a beragadt, elhalt vagy hibára futó jobokat a végén a run sorban fogjuk megtalálni.
Végezetül nézzük a script.sh-t
#!/bin/bash
# This is only a dummy example
echo "Start processing $1"
sleep 5
echo "Finish processing $1"
Még egyszer: ez egy minta alkalmazás, nem csinál semmit. Így itt csak kiírja, hogy elkezdődött a feldolgozás, alszik 5 másodpercet majd kiírja, hogy végzett. Amikor tartalommal kezdjük feltölteni, csak arra kell figyelni, hogy a keletkező adatokat valamilyen külső helyen tároljuk, ne ebben az eldobható konténerben. Ez lehet egy külső SQL, vagy valamilyen megosztott tároló, amilyen az S3. Vagy akár egy olyan Redis szerverre, amiben meg van oldva az adatok mentése és visszaállítása, szemben a példánkban használt megoldással. Mondjuk egy a felhő szolgáltató által biztosított hosted Redis megoldásra.
Használat
Az indításhoz adjuk ki a következő parancsot:
docker-compose up -d
Ha szeretnénk látni mi történik a motorháztető alatt két terminál ablakra lesz szükségünk. Az egyikbe “indítsuk el” a monitort:
docker-compose logs -f
A másikban pedig bátra adjunk hozzá két-három job-ot:
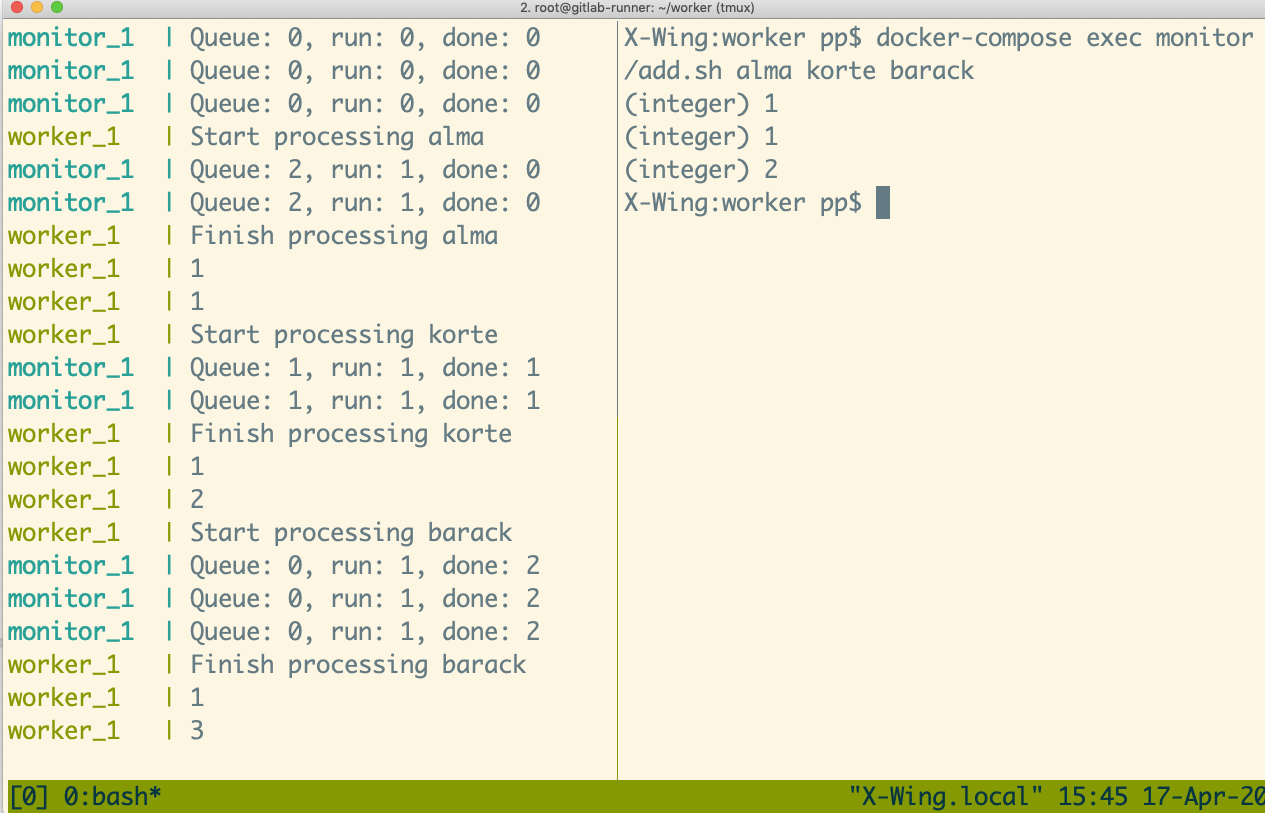
docker-compose exec monitor /add.sh alma korte barack
Ha mindent jól csináltunk valami ilyen eredményt kell látnunk:

A korábban említett skálázást a docker-compose scale kapcsolójával tudjuk hangolni. Például, ha három workert szeretnénk indítani
docker-compose up -d --scale worker=3
Ha ismét csak egy workerre van szükség, akkor:
docker-compose up -d --scale worker=1
Figyeljük meg, ha volt job amin “dolgozott” egy worker, akkor az a run sorban marad, valamint azzal is kell majd valamit kezdenünk, hogy ne olyan lassan álljanak le a workerek. Mindkettő forrása az, hogy a jelenlegi megoldás nem foglalkozik a signálokkal, pedig a Docker alapból lehetővé teszi, hogy graceful shutdown-t hajtsunk végre, vagyis leállításkor visszategyük a feldolgozatlan jobot a queue sorba. Ez azonban már egy másik cikk témája.
Amennyiben befejeztük a játékot, akkor adjuk ki a következő parancsot:
docker-compose down
Összefoglalás
Mint látható a Docker segítségével könnyedén tudjuk skálázni az alkalmazásunkat. Természetesen erre a futtatni kívánt alkalmazást is fel kell készíteni, de ezzel a cikkel csak az a célom, hogy bemutassam, egy ilyen architektúrát felépíteni viszonylag egyszerű a Docker és a Redis segítségével.
Egy következő cikkben működő példát is szeretnék összerakni, hogy lássátok az általatok használt eszközökkel, hogyan lehet ezt megtenni. Amennyiben van konkrét projekt amit szeretnél párhuzamosítani, keress meg nyugodtan az istvan at palocz pont hu email címen, vagy a fészen.
Ha érdekel hogyan tudod fejelsztőcégedet teljesen átállítani a Docker használatára nézd meg a “Konténerizált fejlesztői környezet kialakítása” c. kurzusom.